Technical notes
2023 NSHS data collection and reporting methodology
Introduction
This appendix provides an overview of the 2023 National Social Housing Survey (NSHS) data collection and reporting methodology. Further information on the 2023 NSHS methodology, including a copy of the final questionnaire, can be found in the 2023 NSHS methodological report prepared by Lonergan Research, available in the Related material section of this report.
Data collection
The data quality statement for the 2023 NSHS is available online. Key information is as follows.
Survey scope
The 2023 NSHS collected information from tenants of 4 social housing programs – public housing (PH), community housing (CH), state owned and managed Indigenous housing (SOMIH), and Indigenous community housing (ICH).
Data collection methodology
Among PH, CH and SOMIH tenants (the latter South Australia and Tasmania only), the 2023 NSHS was conducted via a mail-out paper questionnaire, with an option provided for online completion.
Among SOMIH tenants in New South Wales and Queensland and a small number of ACT Community housing tenants, the 2023 NSHS was conducted via face-to-face interview. Face-to-face interviews were also conducted for all ICH tenants in Queensland. Where tenants were not at home, a drop-at-home survey pack was left at the property.
The 2023 NSHS used the same survey instrument across all housing programs, with the exception of 5 state-specific questions for Queensland. Before 2010, the survey content differed slightly across programs, reflecting different areas of interest in relation to each program. Since 2012, the adoption of more consistent survey instruments has allowed greater data comparability across social housing programs. See the Related materials for more information.
Each state and territory provided information for each tenancy and each social housing program to Lonergan Research. To protect tenancy privacy and confidentiality, information was handled in line with relevant legislation. All remoteness areas were included in the sample. For the postal component of the survey, various factors (see Survey and interview response rates) may have affected the number of responses received from tenants in these areas.
Sample design
Consistent with 2021, stratified sampling was undertaken to reduce sampling error and to maximise the chance that state and territory/ program sample targets were met. Minimum sample quotas were again employed for remoteness-based strata. For New South Wales, additional stratification was undertaken based on Department of Communities and Justice districts. Quotas were set for each jurisdiction/housing strata, as shown in Table A1. The actual responses received are shown in Table A2.
Jurisdiction | PH | SOMIH | CH | ICH |
|---|---|---|---|---|
| NSW | 500 | 500 | 540 | n.a. |
| Vic | 500 | . . | 350 | n.a. |
| Qld | 1000 | 500 | 500 | 500 |
| WA | 500 | . . | 350 | n.a. |
| SA | 500 | 300 | 700 | n.a. |
| Tas | 400 | 200 | 400 | n.a. |
| ACT | 500 | . . | 200 | . . |
| NT | 500 | n.a. | n.a. | n.a. |
. . Not applicable (state or territory does not have the program)
n.a. Not available (state or territory not in scope for the 2023 NSHS in the program)
Survey and interview response rates
The response rate for the mail-out/online component of the 2023 NSHS was 26%; for face-to-face interviews, it was 65%. Some non-response bias is expected. The Sample alignment with administrative data section examines key differences between the sample population and the actual population – therefore providing some indication of the potential for non-response bias. Apart from sample weighting (see Weighting following this section), no adjustments have been made for non-response bias.
Changes to the management of tenant privacy has meant that Lonergan Research was unable to be provided with personal information for most tenants in both 2021 and 2023. Letters were instead addressed ‘to the tenant’, which impacted on response rates, partly because individuals are more likely to open mail that is addressed to them personally. Where no personal information was provided, tenants could not be sent digital reminders which also contributed to a drop in response rates.
Slower postal services since the COVID 19 pandemic also impacted on response rates in 2023. Response rates by housing program and state and territory are provided in Table A2.
PH Responses (no.) | PH Response rate | CH Responses (no.) | CH Response rate | SOMIH Responses (no.) | SOMIH Response rate | ICH Responses (no.) | ICH Response rate | |
|---|---|---|---|---|---|---|---|---|
| NSW | 457 | 22.1 | 529 | 23.1 | 548 | 56.4 | n.a. | n.a. |
| Vic | 517 | 27.3 | 344 | 22.6 | . . | . . | n.a. | n.a. |
| Qld | 941 | 24.9 | 502 | 29.3 | 512 | 68.0 | 483 | 74.8 |
| WA | 500 | 32.2 | 336 | 30.9 | . . | . . | n.a. | n.a. |
| SA | 500 | 37.1 | 653 | 25.1 | 226 | 18.1 | n.a. | n.a. |
| Tas | 397 | 33.7 | 384 | 25.4 | 27 | 16.5 | n.a. | n.a. |
| ACT | 524 | 32.9 | 167 | 22.9 | . . | . . | . . | n.a. |
| NT | 464 | 17.5 | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
Notes
- For the mail-out/online component, the response rate was calculated as the number of completed surveys returned as a percentage of the total tenants mailed (excluding any that were returned to sender). For face-to-face surveys, the response rate was calculated as the number of completed interviews as a percentage of the total number of interviews attempted.
- SOMIH tenants were surveyed via face-to-face interviews in New South Wales and Queensland, and ICH tenants were also surveyed face-to-face. South Australia and Tasmania SOMIH tenants were surveyed via mail out. Response rates between the 2 methodologies are not directly comparable.
Weighting
Consistent with the 2021 NSHS, a grouped weighting methodology was employed. Population groups were created across 3 variables: housing type, state and territory, and remoteness. The weighting was calculated as follows: the number of households in each population group divided by the number of usable survey responses. All population counts were confirmed by the states and territories.
Sampling error
The estimates are subject to sampling error. Relative standard errors (RSEs) are calculated for findings from the 2023 NSHS to help the reader assess the reliability of the estimates. Only estimates with RSEs of less than 25% are considered sufficiently reliable for most purposes. Results subject to RSEs of between 25% and 50% are marked as such and should be interpreted with caution. Those with RSEs greater than 50% are considered too unreliable and are not published. To help interpret the results further, 95% confidence intervals (the estimate plus or minus 2 standard errors) are available online as supplementary tables to the 2023 NSHS.
Non-sampling error
The estimates are subject to both sampling and non-sampling errors. The survey findings are based on self-reported data. Non-sampling errors can arise from errors in reporting of responses (for example, failure of respondents’ memories or incorrect completion of the survey form), or the unwillingness of respondents to reveal their true responses. Further non-sampling errors can arise from coverage, interviewer or processing errors. It is also expected that there is some level of non-response error where there are higher levels of non-response from certain subpopulations.
Comparability with previous NSHSs
Surveys in this series began in 2001. Over time, the survey’s methodology and questionnaire design have been modified. The sample design and the questionnaire of the 2023 survey differ in some minor respects from previous versions of the survey. Further details are available in Related materials.
The revisions of the survey undertaken for the 2021 NSHS were the most substantial since 2012. These revisions included some restructuring of sections, changes to question wording, the addition of COVID 19 pandemic-related questions and new state-specific questions (for South Australia PH/SOMIH and the Australian Capital Territory PH). For 2023, the COVID-19 pandemic-related questions were removed and replaced with questions relating to neighbours and wellbeing.
The 2023 NSHS sampling and stratification methods were similar to those for the 2021 survey: a sample was randomly selected from each stratum. Some additional location-based stratification was undertaken for New South Wales in 2021 and 2023.
Caution should be used when comparing NSHS trend data or data between states and territories due to differences in response rates and non-sampling errors. Some substantial decreases in response rates for mail-out surveys were observed in 2021 and response rates were largely stable moving into 2023.
As in 2016, 2018, and 2021, the data collected for SOMIH was sourced using 2 methodologies: via mail-out and via face-to-face interview. Since 2016, the mail-out approach was used for SOMIH tenants in South Australia and Tasmania and the face-to-face approach was used for SOMIH tenants in New South Wales and Queensland. In 2021 the approach in Queensland for these tenants changed from face-to-face (used in 2016 and 2018) to mail-out due to COVID-19 pandemic restrictions. This reverted back to face-to-face in 2023.
Different methodologies not only influence the overall response rate, but also have potential impacts on the completion of each question and how tenants perceived and responded to questions. Trend data from before 2016 (and also in 2016 and 2018 for Queensland) and comparisons between states and territories, should therefore be interpreted with caution.
Refer to data quality statements for the 2014 NSHS, 2016 NSHS, 2018 NSHS and 2021 NSHS and their accompanying technical reports before comparing data across surveys.
Reporting methodology – respondents versus households
Responses to the NSHS can report information:
- about the social housing tenant completing the survey (the respondent), such as age and gender
- that refers to themselves and other individuals in the social housing household, such as whether there are any adults in the household currently working full time
- on behalf of all members of their household, such as whether the location of their dwellings meet the needs of the household.
In each instance, this is noted under the relevant chart or table throughout the report.
It is important to distinguish between household-level responses and responses to those questions that specifically target the individual who completed the survey. Responses related to the individual completing the survey may not apply to other members of the household.
It should also be noted that, where survey respondents have provided information on behalf of other household members, they have not been asked if they had consulted members in formulating their responses.
Missing data
Some survey respondents did not answer all questions, either because they were unable or unwilling to provide a response. The survey responses for these people were retained in the sample, and the corresponding values were set to missing. Cleaning rules resulted in the imputation of responses for some missing values. Missing responses were excluded from the numerator and denominator of estimates presented in this report.
Sample alignment with administrative data
As part of the NSHS, tenants who responded to the survey were asked to report the gender and age of all members of their household; they were also asked questions to establish if anyone in the household was Indigenous or had a need for assistance due to disability. Table B1 compares the age and gender distribution of all 2023 NSHS household members with similar information from administrative data collections. The distribution of 2023 NSHS households across selected household-level characteristics is also compared with corresponding information from administrative data collections.
For this analysis, the 2023 NSHS data were weighted. Weighting helps account for over- or under-representation of particular groups of tenants in the responding sample, to the extent that these differences reflect differences across states and territories by remoteness and housing program categories (these are the groups, or strata, used to determine weights for sample responses).
As Table B1 shows, while there was broad alignment between the 2023 NSHS and administrative data results, there were also some differences, particularly among SOMIH households. This may be partly due to the much smaller size of that program, so that relatively small differences in numbers would lead to greater differences in proportions.
Within PH and CH, tenants aged 5–17 appeared to be under-represented in the NSHS, compared with administrative data, while the profile of NSHS SOMIH tenants was younger than in the administrative data. SOMIH was conducted via face-to-face interviews in New South Wales and Queensland which contributed more than one-third of the total SOMIH sample. It may be that the different collection methodologies resulted in different response biases.
One characteristic recording a noticeable difference between 2023 NSHS results and the corresponding information drawn from administrative data is household composition. For all programs, the proportion of sole parents with children was markedly higher in the NSHS than in the administrative data collections, and the proportion of group or mixed composition households was lower in the NSHS.
While most of the NSHS analysis in this report drew on information about the entire time a tenant had been living in social housing, in Table B1, NSHS information about time in the current home was used, as that information would more closely compare with information about tenure length from administrative data collections. Even so, it appeared that households who had been in social housing for longer were over-represented in the NSHS, particularly among SOMIH tenants.
Finally, there were some discrepancies between the NSHS and administrative data in the proportions of Indigenous households, and households where there was one or more household member with disability.
| Gender (all occupants) | PH NSHS 2023 | PH Admin. data | SOMIH NSHS 2023 | SOMIH Admin. data | CH NSHS 2023 | CH Admin. data |
|---|---|---|---|---|---|---|
Males | 40 | 44 | 44 | 45 | 39 | 44 |
Females | 49 | 56 | 53 | 55 | 51 | 55 |
| Other/not stated | 11 | 1 | 3 | 0 | 9 | 1 |
| Age (years) (all occupants) | PH NSHS 2023 | PH Admin. data | SOMIH NSHS 2023 | SOMIH Admin. data | CH NSHS 2023 | CH Admin. data |
|---|---|---|---|---|---|---|
Under 5 | 4 | 4 | 8 | 5 | 4 | 5 |
5 to 17 | 16 | 21 | 29 | 31 | 12 | 19 |
| 18 to 24 | 5 | 7 | 11 | 12 | 7 | 9 |
25 and over | 69 | 67 | 50 | 52 | 68 | 67 |
| Not stated | 6 | 0 | 1 | 0 | 9 | 1 |
| Household composition | PH NSHS 2023 | PH Admin. data | SOMIH NSHS 2023 | SOMIH Admin. data | CH NSHS 2023 | CH Admin. data |
|---|---|---|---|---|---|---|
Single adult | 57 | 58 | 24 | 21 | 61 | 62 |
Couple only | 9 | 7 | 5 | 4 | 10 | 5 |
Sole parent with dependent children | 17 | 13 | 36 | 26 | 14 | 11 |
| Couple with dependent children | 5 | 3 | 11 | 8 | 4 | 2 |
Group and mixed composition | 4 | 16 | 21 | 41 | 4 | 2 |
| Not stated | 8 | 4 | 3 | 1 | 6 | 5 |
| Tenure length (years) | PH NSHS 2023 | PH Admin. data | SOMIH NSHS 2023 | SOMIH Admin. data | CH NSHS 2023 | CH Admin. data |
|---|---|---|---|---|---|---|
2 years or less | 14 | 14 | 15 | 14 | 22 | n.a. |
Over 2 to 5 years | 17 | 17 | 17 | 21 | 20 | n.a. |
| Over 5 to 10 years | 16 | 20 | 17 | 23 | 19 | n.a. |
Over 10 to 15 years | 13 | 12 | 12 | 18 | 17 | n.a. |
| Over 15 to 20 years | 10 | 10 | 9 | 6 | 6 | n.a. |
Over 20 years | 27 | 19 | 30 | 10 | 14 | n.a. |
| Not stated | 3 | 7 | 1 | 8 | 3 |
| Indigenous household status | PH NSHS 2023 | PH Admin. data | SOMIH NSHS 2023 | SOMIH Admin. data | CH NSHS 2023 | CH Admin. data |
|---|---|---|---|---|---|---|
Indigenous household | 12 | 14 | 97 | 100 | 13 | 11 |
| Non-Indigenous household | 78 | 66 | 3 | 0 | 79 | 85 |
| Not determined | 9 | 20 | 1 | 1 | 8 | 4 |
| Household disability status | PH NSHS 2023 | PH Admin. data | SOMIH NSHS 2023 | SOMIH Admin. data | CH NSHS 2023 | CH Admin. data |
|---|---|---|---|---|---|---|
Person(s) in household with disability | 27 | 40 | 15 | 20 | 24 | 30 |
| No person in household with disability | 71 | 50 | 84 | 44 | 74 | 65 |
| Not determined | 2 | 11 | 1 | 36 | 2 | 5 |
Note:
- Components within each characteristic may not add to 100% because of rounding.
- ICH has not been included in this table due to limited information at this level of detail
Sources: AIHW National Housing Assistance Data Repository; NSHS 2023.
Regression analysis – details
Regression analysis of NSHS data to examine the statistical relationships between multiple explanatory factors and tenant satisfaction. This type of statistical technique shows which individual factors are significantly associated with tenant satisfaction, after simultaneously accounting for the confounding effects of the other factors included in the model (see, for example, Sperandei 2014).
In particular, regression analysis was used to help answer the following key questions:
- What are the most important factors associated with tenant satisfaction, after accounting for differences in geography, demographic and housing-related factors?
- Do the factors associated with satisfaction differ depending on the type of housing program?
- How do we account for apparent differences in satisfaction between different populations? What factors best explain the observed differences?
This appendix provides a detailed description of the regression analysis method and results.
Method
Logistic regression was the statistical technique used for this analysis. Logistic regression is an appropriate analytical technique to use when the outcome variable has 2 categories. In the analysis used for this report, the outcome variable had 2 categories: whether the social housing tenant was satisfied (satisfied or very satisfied) or not satisfied (neither satisfied nor dissatisfied, dissatisfied or very dissatisfied) with the services provided by their housing organisation.
A regression model was developed that included variables available in the NSHS data set (referred to as factors in this report) that had been identified in previous analyses as being potentially related to tenant satisfaction, along with key geographic, psychosocial and sociodemographic factors (Table C1). This model (Model 1) was used to analyse all social housing tenants in the 3 main programs combined – PH, CH and SOMIH. Similar models were used to analyse tenants within each program – (Models 2–4). The only differences in Models 2–4 compared with Model 1 were:
- Models 2–4 did not include housing program as a variable, as each was single-program only.
- Model 3 (SOMIH) did not include the variable Whether Indigenous household as the SOMIH program is specifically targeted at Indigenous households.
More information about the variables used in the analysis is provided in Table C1. To have a point of reference, so that the direction and size of a factor’s relationship with satisfaction can be seen, a base case (reference category) is assigned for each variable in the model (for example, for the variable housing program, the base case is PH). The reference group is a hypothetical group of tenants with all the base case characteristics combined.
Base cases for each variable were selected because they provide a useful point of reference – for example, they were the bottom or top of a variable range (for example, age group 0–34, education less than Year 10, employed); they represented the most common group (for example, PH, major cities, Non-Indigenous households, households without disability, no children in household, no structural problems, 7 working facilities, ‘adequate’ home utilisation, house as the previous dwelling type, no experience of homelessness in the last 5 years, very comfortable asking neighbour for help, no experience of household income going down, no experience of struggling to pay rent or bills, no experience of high level of worry or anxiety, no experience of high level of loneliness or isolation, no experience of difficulties in personal relationships); or they represent a benchmark for tenant satisfaction (for example, Queensland, and living in social housing for 0–5 years).
The logistic regression analyses were conducted in R using the ‘svyglm’ function to incorporate survey design and weights. The survey weight was included in these analyses to partly account for over- or under-representation (by housing program, state/territory and remoteness and program type) of particular groups of tenants in the responding sample.
| Variable/category | Variable construction |
|---|---|
| Outcome variable: | Outcome variable: |
Tenant satisfaction Satisfied Not satisfied | Observations with invalid or missing responses were excluded from the analysis. Satisfied = Very satisfied or satisfied Not satisfied = Neither satisfied nor dissatisfied, Dissatisfied, Very dissatisfied |
| Explanatory variables (factors) | Explanatory variables (factors) |
| State/territory NSW, Vic, Qld (base case), WA, SA, Tas, ACT, NT | As recorded. No missing or invalid responses. |
Remoteness Major cities (base case), Inner regional, Outer regional, and Remote/very remote | Categories ‘Remote’ and ‘Very remote’ were combined. No missing or invalid responses. |
Age group (years) 0–34 (base case) 35–44, 45–54, 55–64, 65 and over | Observations with invalid or missing responses were excluded from the analysis. Self-reported continuous age of the main tenant was grouped into categories. |
Highest level of education Bachelor degree or above, Certificate, Apprenticeship, Diploma or Advanced Diploma, Years 11–12, Year 10, lower than year 10 (base case) | Observations with invalid or missing responses were excluded from the analysis. Categories ‘Year 11’ and ‘Year 12’ were combined. Categories ‘Did not go to school’, ‘Year 6 or below’, ‘Year 7’, ‘Year 8’ and ‘Year 9’ were combined. |
Employment status Employed (base case) Not employed | Observations with invalid or missing responses were excluded from the analysis. |
Whether Indigenous household (this factor not in SOMIH model) Indigenous household Household not Indigenous (base case) | Observations with invalid or missing responses for any of the relevant questions were excluded from the analysis. Classified as Indigenous if tenant identified that they or another member of their household were Indigenous. Classified as non-Indigenous if tenant (a) did not identify any member of their household (including themselves) as Indigenous and (b) identified that they (and any other members of the household) |
Whether person with disability in household One or more persons with disability in household, other households (base case) | Observations with invalid or missing responses for the relevant questions were excluded from the analysis. Classified as at least one person with disability in household if tenant identified that they or another member of their household had difficulties seeing, hearing, walking or climbing stairs, remembering or concentrating, self-care or communicating using usual language due to a long-term physical, mental or emotional health condition. Else classified as no household members with disability. |
| Children in household One or more children in household, no children in household (base case) | Observations with invalid or missing responses were excluded from the analysis. Classified as one or more children in household if the household includes at least one tenant aged under 18. Else classified as no children in household. |
Housing program Public housing (base case), community housing, state owned and managed Indigenous housing | As recorded by fieldwork provider No missing or invalid responses. |
Number of structural problems 0 (base case), 1, 2, 3+ | Observations with invalid or missing responses were excluded from the analysis. |
Number of working facilities 0–6, all 7 nominated (base case) | Observations with invalid or missing responses were excluded from the analysis. |
Housing utilisation Overcrowded, Adequate (base case), Underutilised | Observations with invalid or missing responses to the relevant questions were excluded from the analysis. Refer to Canadian National Occupancy Standard definition in Glossary. |
Time living in social housing (years) 0–5 (base case), 6–10, 11–15, 16+ | Observations with invalid or missing responses were excluded from the analysis. Categories ‘Less than a year’, ‘1–2 years’ and ‘3–5 years’ were combined, categories ’16–20’ and ’21 or more’ were combined. |
Previous dwelling type House/ townhouse/ flat (base case), Other than a house/ townhouse/ flat | Observations with invalid or missing responses were excluded from the analysis. All categories other than ‘House/townhouse/flat’ were combined into a single category, comprising caravan/cabin/boat/mobile home, no dwelling/improvised dwelling/motor vehicle/tent, and temporary accommodation/institution/other. |
Previous homelessness Had not experienced homelessness in the last 5 years (base case), Had experienced homelessness in the last 5 years. | Observations with invalid or missing responses were excluded from the analysis. Classified as having experienced homelessness in the last 5 years. |
Neighbours Very comfortable asking for help (base case), comfortable, neither comfortable nor uncomfortable, uncomfortable or very uncomfortable. | Observations with invalid or missing responses were excluded from the analysis. Uncomfortable and very uncomfortable combined. |
Wellbeing Had not experienced household income going down (base case), Had experienced household income going down | Observations with invalid or missing responses were excluded from the analysis. |
Results
The results from the regression analysis are in the form of predicted probabilities. These are the likelihood, estimated by the models, of a tenant’s reporting that they are satisfied given they hold a particular set of characteristics (a category for each of the factors included in the model). This can be compared with the predicted probability for the reference group, who hold all the base case characteristics. A higher probability for a particular category (say, the category community housing for the factor housing program), when compared with the reference group, indicates that the category of interest (in the example just given, CH) is positively associated with tenant satisfaction in comparison to the base case (for housing program the base case is PH). A negative difference between the category of interest and the reference group indicates a negative association (for example, SOMIH versus the base case of PH).
The predicted probability (expressed as a percentage) was derived from the R ‘svyglm’ outputs, which were in the form of odds and odds ratios. This was done as follows (see ABS 2012; Eckel 2008):
Step 1. The predicted probability for the reference group was calculated. The log-odds for the reference group is reported in the R output as the model intercept. To convert this to a predicted probability, the log-odds was converted to odds by exponentiating the log-odds. The odds was then converted to a predicted probability using the formula:
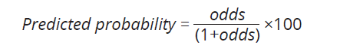
Step 2. The odds ratio (exponentiating the model coefficients of the R output) for each factor category was applied to the reference group odds (obtained from Step 1) to obtain the odds for that factor category (with all other factors having the reference category values). This was then converted to a predicted probability using the formula provided in Step 1.
Step 3. The difference between the predicted probability for the factor category and the reference group was obtained.
Table C2 shows the predicted probability of the reference group for each model, and the number of observations for each.
| M1 – All tenants | M2 – PH only | M3 – SOMIH | M4 – CH | |
|---|---|---|---|---|
Predicted probability of reference group (%) | 94 | 96 | 91 | 91 |
| Number of observations | 5795 | 2819 | 1006 | 1972 |
Note: See Table C1 for the base case for each variable in the models – these are the characteristics of the reference groups
Factor by factor, the regression results presented in Table R.3 show:
- The predicted probability of satisfaction for a tenant with the characteristics of the reference group (the base case categories combined), except in the factor of interest (category as shown).
- The p value of model estimates – this indicates the level of confidence we can have in there being a relationship between a factor category and the outcome (satisfaction). The smaller the p value, the greater the confidence of an association between the factor and the outcome. A typical convention is to describe p values of less than 0.05 as being statistically significant (with a 95% level of confidence). However, there may be results that do not meet this standard but are still of importance or interest (perhaps they complement/align with other findings, or the magnitude of the association is large). Conversely, not all differences with a p value < 0.05 are necessarily important or noteworthy, especially if the effect is small.
An example will illustrate how to use the results from Table R.3 by examining the factor structural problems using Model 1 (M1). The preceding table (Table C2) shows the predicted probability of being satisfied for the reference group in M1 is 94%. The base case for the factor structural problems is 0 structural problems in the home. The results presented in Table R3 for the categories 1 structural problem through to 3 or more structural problems allow us to see the predicted change in satisfaction when comparing tenants with no structural problems to tenants with one or more, while holding all other factors constant. The predicted probability in M1 of being satisfied for tenants living with 3 or more structural problems is 76%. This is substantially lower than the probability of being satisfied for the reference group (94%), with a category of 0 structural problems. Not only is the effect large, it is also statistically significant (p<0.0001).
Abbreviations and symbols
| Term | Meaning |
|---|---|
AIHW | Australian Institute of Health and Welfare |
| CNOS | Canadian National Occupancy Standard |
| CH | community housing |
| CI | confidence interval |
| ICH | Indigenous community housing |
| NSHS | National Social Housing Survey |
| PH | public housing |
| RSE | relative standard error |
| SOMIH | state owned and managed Indigenous housing |
| Symbol | Meaning |
|---|---|
| . . | not applicable |
| n.a. | not available |
| n.p. | not published because of small numbers, confidentiality or other concerns about the quality of the data |